社内の DX を進めていく中でアナログデータを OCR するという要件がそこそこあるのですが、お堅い企業だとクラウド利用禁止だったり低スペ PC しかなかったりの制約があり、エッジで動作する汎用 OCRで何か良いのないかなーと探していたら、素晴らしいライブラリを見つけました。
日本語で紹介している記事が全く見つからなかったので、AI 驚き屋みたいに紹介していきます。
OnnxOCR とは
OnnxOCRとは、PaddleOCRをベースにした軽量な OCR でpaddlepaddle深層学習フレームワークなしでも動作し、高速な推論速度を備えています。
PaddleOCRと同じモデルをonnxモデルに変換すると、精度とパフォーマンスが向上し、推論速度は paddlepaddle フレームワークを使用する場合よりも 5 倍速くなります。
簡単に言うと従来の OCR エンジンと比較すると圧倒的に高速高性能な OCR エンジンです。
また、Apache ライセンスなので商用利用も可能です。
使い方
インストールは PYPI からできます デフォルトでライブラリデータ内に onnx モデルを DL するので、すぐに使い始められます。
pip install onnxocr使い方も非常に簡単で以下のようなプログラムで OCR が実行できます。
from onnxocr.onnx_paddleocr import ONNXPaddleOcr
def sample():
ocr = ONNXPaddleOcr(use_gpu=False, lang="japan")
result = ocr.ocr("sample.png")
for data in result:
for box, (text, score) in data:
print(f"text: {text}, score: {score}")ONNX とは
OnnxOCR を紹介する上で ONNX とは何ぞやということも軽く解説します。 ONNX(Open Neural Network Exchange)とは、機械学習モデルを異なるフレームワーク間で共有・運用するためのオープンなフォーマットです。
このフォーマットに従うことで、PyTorch、TensorFlow、Scikit-learn など、異なる機械学習フレームワークで作成されたモデルを、共通の形式で保存・読み込みできるようになります。
ハードウェアベンダーは ONNX に最適化を施すことで、複数のフレームワークに対応した高速な推論環境を提供できます。
そしてONNX Runtimeというエコシステムが非常に協力で、これによって高速な推論を可能にしています。
つまりOnnxOCR は PaddleOCR を ONNX の強力なエコシステムを使うことで高速化したライブラリということになります。
実際に速度と精度を比較してみる
言葉だけで紹介しても凄さが伝わらないので実際に検証してみます。
検証条件は以下のとおりです。
-
EasyOCR、PaddleOCR、OnnxOCRの3つで比較
-
モデルはEasyOCRはデフォルト設定、PaddleOCRとOnnxOCRはそれぞれ同じモバイル向けの軽量モデルを使用
-
CPU 推論のみ(Intel 製 12 世代 Core i7 を使用)
Tesseractは上記3つとは少し毛色が違うので今回は比較しませんでした。
比較 ① (風景に写る案内表示)
以下の画像を使用しました。

町中の案内表示
各 OCR エンジンの認識結果は以下です。
- EasyOCR

- PaddleOCR

- OnnxOCR

- 速度ベンチマーク
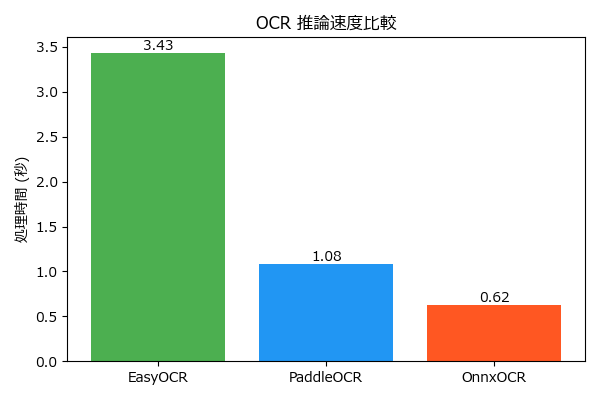
認識精度に関してはどの OCR エンジンも概ね正確に認識できました。 注目すべきは推論速度です。 速度ベンチマークグラフを見て分かる通り、OnnxOCR の推論速度が 0.62 秒と最も高速です。認識精度との兼ね合いを考慮するとものすごい性能です。
比較 ② (文字の多い文書)
次は文書ファイルのような綺麗な文字の画像を渡してみます。文字数は多めですがどうでしょうか。

- EasyOCR

- PaddleOCR

- OnnxOCR

- 速度ベンチマーク

文字の多い文書のデータでは推論速度に大きな差はでませんでしたが、OnnxOCR が最速となりました。
推論に最も時間のかかる EasyOCR と認識精度が同じなのは凄いです。
比較 ③ (文字は少ないが変形している画像)
最後に以下の画像を検証しました。

- EasyOCR

- PaddleOCR

- OnnxOCR

- 速度ベンチマーク

比較 ③ ではOnnxOCRが圧倒的な成績を出しました。
何も設定していませんがOnnxOCRだけ傾き補正もしっかり効いて高い文字認識をしています。
また、推論速度ではPaddleOCRの2 倍、EasyOCRの7.5 倍高速に動作しました。
ただ、EasyOCR はどの画像でも 3.5 秒ほどで完了しているので、対象の実際の情報量にあまり影響されないのかもしれません。
おわりに
大前提モデルの性能に依存するところはありますが、OnnxOCRは軽量ながら情報量の少ない画像データでは圧倒的な推論速度・文字認識を誇ることがわかりました。
このレベルのモデルをオープンソースで公開する Baidu(百度)は恐ろしいですね。
CPU 推論でもこれだけの性能が出れば、かなり実用的な OCR 処理がエッジ環境でも実行できそうです。
ONNX に非常に興味が湧いたのでもう少し色々調べてみたいと思います。
