
こんにちは、ローカルマシンで頑張りたい協会のハルミです。
以前、ローカル OCR ライブラリを紹介して結構な反応がありました。今回はこちらのライブラリを活用してみる編ということで記事を書いてます。
スキャン PDF って何かと不便
スキャン PDF が何なのか一応説明しておくと、プリンターなどでスキャンして PDF データに変換された、テキストデータが全く無い PDF ファイルのことです。
これの何が厄介かというと、
-
テキストの検索・コピーができない
-
AI 活用しにくい
みたいなことがあります。
~~こんなこと説明されなくても社会人の皆さんは常々思っていることではあると思いますが...~~
Google ドライブとかにアップロードしたりすれば簡単にテキスト化処理出来ますが、例のごとく社内制約によって使えずなので何かいい方法はないか...🤔
そうだ、Python で無料でテキスト埋込しよう
前置きはこの辺にしておいて、完全ローカルで既存の PDF 上に透明テキストを埋め込み、検索可能 PDF(Searchable PDF)に変換していくプロセスを作っていきましょう。
記事では簡単のため、少し簡素化した処理を紹介してます。
記事の最後の方には、こちらで解説したものを簡単に実行できるTUI ツールにしたものも紹介してますので、利用だけしてみたい方はセクション飛ばしてどうぞ!
必要パッケージのインストール
パッケージマネージャーにはuvを使用していきます。
uv init
uv add numpy opencv-python pypdf pypdfium2 reportlab onnxocrpip install numpy opencv-python pypdf pypdfium2 reportlab onnxocr| ライブラリ | 目的 | | ---------- | ------------------------------------- | | numpy | OCR の前処理 | | OpenCV | OCR の前処理 | | pypdf | 元の PDF へオーバーレイ PDF を合成 | | pypdfium2 | PDF ページを画像としてレンダリング | | reportlab | テキストレイヤーを描画した PDF を作成 | | OnnxOCR | CPU 推論で高速 OCR 処理 |
全体フロー
処理の概念図は以下の通りです。
flowchart TD
A(PDF) -->| 画像化 | B[OCR]
B --> C[テキスト位置取得]
C --> D[ 透明テキストPDF作成]
D --> E[元PDFと合成]
E --> F(完成!)各ステップを分解して、簡単なサンプルコードで説明していきます。
1. PDF ページを画像(PIL Image)として取り出す
OCR を行うには PDF を画像に変換する必要があります。 ここで使うのが pypdfium2 です。
import pypdfium2 as pdfium
def render_pdf_to_image(pdf_path, dpi=300):
pdf = pdfium.PdfDocument(pdf_path)
page = pdf[0] # 例:最初の1ページのみ
scale = dpi / 72
pil_img = page.render(scale=scale).to_pil()
return pil_imgポイント
-
PDF は 72dpi ベース → OCR のために 300dpi 前後へスケールアップ
-
to_pil()で Pillow 画像になるので、OpenCV や numpy で扱える
2. OCR の実行
別記事にて紹介した OnnxOCR を使って PDF 画像を OCR していきます。
import numpy as np
import cv2
from onnxocr.onnx_paddleocr import ONNXPaddleOcr
ocr = ONNXPaddleOcr(use_gpu=False, lang="japan")
def run_ocr(pil_img):
rgb = np.array(pil_img)
bgr = cv2.cvtColor(rgb, cv2.COLOR_RGB2BGR)
results = ocr.ocr(bgr)
return results
OnnxOCR の実行結果は以下のようなデータが格納されています
[
[
[[x1,y1], [x2,y2], [x3,y3], [x4,y4]], ["文字列", 信頼度]
],
...
]3. OCR 結果を“矩形+テキスト”に正規化する
こちらの処理は無くても問題ありませんが、OCR 結果は 4 点の四角形(クアッド)ですが、PDF に文字を押し込むためには **単純な矩形(x1,y1,x2,y2)**が扱いやすいです。後の処理のためにデータを扱いやすくしておきます。
def normalize_ocr_results(ocr_results):
items = []
for line in ocr_results[0]:
quad = line[0]
text = line[1][0]
xs = [p[0] for p in quad]
ys = [p[1] for p in quad]
items.append({
"text": text,
"bbox": (min(xs), min(ys), max(xs), max(ys)),
})
return items
4. ReportLab で「透明テキストレイヤー PDF」を作る
ここがいちばん重要な部分です。
OCR で得た文字位置へ、透明文字(Invisible Text) を配置し、元 PDF に合成すると、“検索可能 PDF”になります。
import io
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
pdfmetrics.registerFont(UnicodeCIDFont("HeiseiKakuGo-W5")) # 日本語フォント
def create_overlay_pdf(page_w, page_h, ocr_items):
buf = io.BytesIO()
c = canvas.Canvas(buf, pagesize=(page_w, page_h))
c.setFillAlpha(0.0) # 完全透明
for item in ocr_items:
x1, y1, x2, y2 = item["bbox"]
text = item["text"]
fontsize = max(6, (y2 - y1) * 0.9)
c.setFont("HeiseiKakuGo-W5", fontsize)
# PDF座標は左下原点なので上下を反転
baseline_y = page_h - y2
c.drawString(x1, baseline_y, text)
c.save()
return buf.getvalue()
ポイント
-
setFillAlpha(0.0) で透明化する
-
OCR 座標は画像座標(上が 0) → PDF は下が 0 → 上下反転が必要
-
y 座標は page_h - y2
:::message alert reportlab はデフォルトでは日本語などを扱えないため、日本語対応フォントを設定しておく必要があります。 ちゃんと使うなら別途日本語対応フォントを用意して読み込んだほうがいいかも
pdfmetrics.registerFont(UnicodeCIDFont("HeiseiKakuGo-W5")):::
5. PyPDF で元 PDF とオーバーレイ PDF を合体する
最後の仕上げです。作成した透明文字の PDF オーバーレイを元の PDF に合体させればいい感じにテキスト埋込 PDF の生成完了です。
from pypdf import PdfReader, PdfWriter
def merge_overlay(original_pdf, overlay_bytes, output_pdf):
reader = PdfReader(original_pdf)
overlay_reader = PdfReader(io.BytesIO(overlay_bytes))
writer = PdfWriter()
page = reader.pages[0]
overlay_page = overlay_reader.pages[0]
page.merge_page(overlay_page)
writer.add_page(page)
with open(output_pdf, "wb") as f:
writer.write(f)
プログラムを実行してみる
記事に掲載できるいい感じのスキャン PDF の素材が見つからなかったので、それっぽい書類データを画像にしたものを PDF に変換してスキャン PDF として処理にかけてみました
 プログラムによってテキストが選択可能になった!
プログラムによってテキストが選択可能になった!
OCR 実行時に返ってくる bbox をもとに座標や文字の大きさを決めているので、実際の文字とはやや位置や文字の大きさはズレてはいますが、いい感じに透明文字を埋め込めています。
ちなみにテキストをコピーして貼り付けた結果は以下のような感じ。やや文字認識にミスがありますが、使用用途によっては十分な認識精度かと思います。
令和7年12月1日
関係者各位
口一力ルOCR実行委員会
委員長ハルミ
スキ一PDF変換大会の開催中止につて(お知らせ
拝啓時下ますます二清祥のこととお喜び申し上げます。平素は当会の運営につき
まして格別のご高配を賜り、厚く御礼申し上げます。
さて、開催を予定しておりました標記のスキPDF変換大会は、委員長の体調不
良のため、慎重な協議の結果、中止が決定いたしましたので、(ここに)お知せ
いたします。
実行委員一同、開催に向けて準備をしてまいりましたが、苦渋の決断をせさるを
得ない状況なりました。開を心待ちにしてくださっていた皆ま、関係者の皆
さまには大変ご迷惑かけすることとな「大変ご迷惑かけいたしますこ
と、深くおび申し上げす。なにとご理解(ご了承いただきますようご
理解(ご了承)のほよろしくお願い申し上げます。
敬具
記
1.イベト[催し物・行事名
2.開催日令和7年12月2日(日)
3.お問↓合わせ先:000-000-0000
以上ここについては OCR の性能によるところが大きいので、この記事ではあまり触れないでおきます。
TUI ツールとして公開しました
以上簡単な処理ですが、この処理を TUI で簡単に実行するための TUI アプリケーションも作って PyPI に公開してみたので、気になる人はよかったら使ってみてください。
TUI の構築にはtextual を使っていて、ターミナルで PDF の OCR→ 検索可能 PDF 生成を行えます。詳しくはREADME をご覧ください。
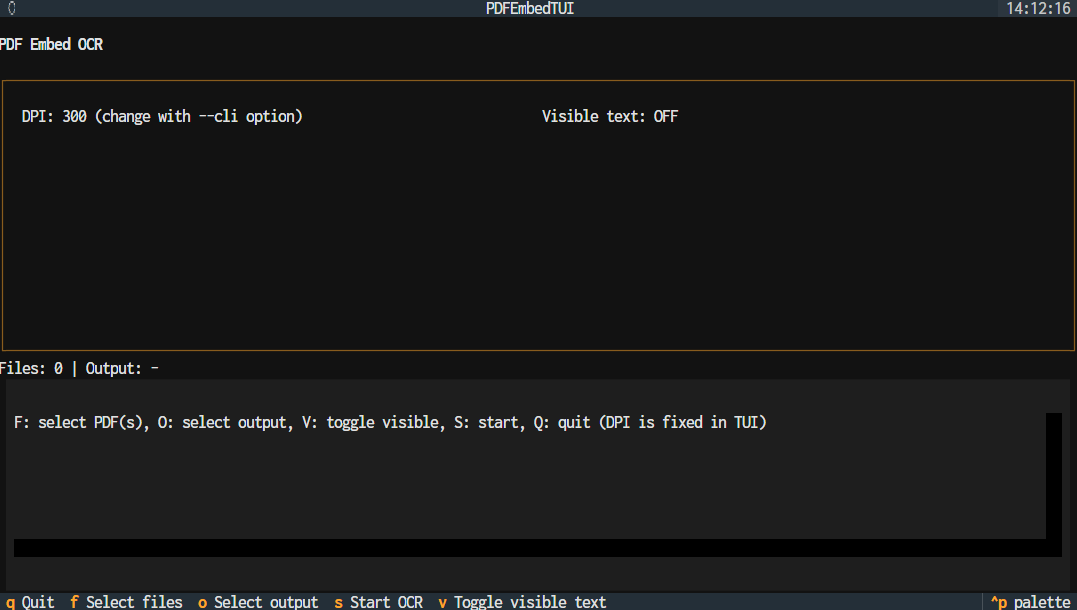 TUI ツールの画面(ターミナル上で動いています)
TUI ツールの画面(ターミナル上で動いています)
https://github.com/harumiWeb/pdfembed
pip install pdfembed
pdfembedおわりに
簡単な解説記事でしたが、実際かなり実用的だったので紹介してみました。 OCR ライブラリ、サービスの多くは文字認識と同時にバウンディングボックスも取得できるので上手く活用できました。
画像認識モデルをローカルで実用的に動かせるようになればもっと実用的なものが作れそうなので、今後の AI の進歩に期待ですね 🔥
それではまた 👋
参考リンク
- TUI ツール作成ライブラリ
https://textual.textualize.io/
